„Ähnliche Namen“ im Archiv der Wiener Staatsoper
Früher war mehr Blogging
Leider finden wir schon lang nicht mehr die Zeit, unser Blog zu befüllen. Die alten Beiträge sind aber weiterhin online, zum Stöbern in der Vergangenheit.
Der folgende Blogbeitrag stammt aus dem Jahr 2018.
Hintergrund zum Projekt
Das Spielplanarchiv der Wiener Staatsoper umfasst rund 40.000 Aufführungen von 1869 bis heute. Für jede Aufführung sind alle beteiligten Personen erfasst – aktuell insgesamt etwa 1 Million Auftritte von 10.000 Personen.
Ursprünglich war dieser Datenbestand nur über einen einzelnen Computer im (inzwischen geschlossenen) Staatsopernmuseum zugänglich. Wir übernahmen das Projekt 2011 mit der Anforderung, dieses Archiv in die Website der Wiener Staatsoper einzubinden. Dazu haben wir eine maßgeschneiderte Webapplikation entwickelt, deren Frontend unter archiv.wiener-staatsoper.at erreichbar ist. Zusätzlich existiert ein Backend, über das der Datenbestand laufend bearbeitet und ergänzt wird.
Der aktuelle Verbesserungswunsch: „Ähnliche Namen beim Anlegen einer Person anzeigen“
Bei über 10.000 erfassten Personen kommt es immer wieder vor, dass eine Person unabsichtlich mehrfach angelegt wird, weil zum Beispiel unterschiedliche Schreibweisen des Nachnamens kursieren.
Um solche Doppeleinträge in Zukunft möglichst zu vermeiden, sollte beim Anlegen einer neuen Person automatisch eine Liste von Personen mit ähnlich klingenden Namen angezeigt werden.
Ähnlichkeitssuche über phonetische Algorithmen
Um „ähnlich klingende“ Namen zu finden, haben wir einen sogenannten phonetischen Algorithmus implementiert. Bekannte Vertreter sind Soundex und Metaphone – beide wurden allerdings für englische Wörter entwickelt und waren daher in diesem Fall keine gute Wahl.
Für deutsche Begriffe eignet sich die Kölner Phonetik. Hier wird jedem Wort ein Zahlencode zugeordnet, der grob die Aussprache dieses Wortes abbildet. Ähnlich klingende Wörter bekommen denselben Code zugeordnet, dadurch können solche Wörter leicht gefunden werden.
Spezialfälle bei komplexen Namen
In der Theorie wäre die Anforderung „finde ähnliche Namen“ mit dem Einbau des passenden phonetischen Algorithmus abgeschlossen. In der Praxis sind die Dinge aber, wie so oft, etwas komplizierter. Ein phonetischer Algorithmus allein wird zum Beispiel in folgenden Fällen keine befriedigenden Ergebnisse liefern:
- Doppelnamen wie „Barton-Jonas“ oder „Gullberg Jensen“
- Namensergänzungen wie in „Hellmesberger jun.“ oder „Strauß (Vater)“
- Herkunftsnamen wie „da Ponte“, „La Fosse“ oder „van Beethoven“
- Komplexe Namen, die mehrere dieser Spezialfälle kombinieren, zum Beispiel „Vernoy de Saint-Georges“
Gemeinsam mit den Personen, die mit der Datenbank arbeiten, haben wir uns daher für alle diese Fälle passende Spezialbehandlungen überlegt, und zusätzlich zum phonetischen Algorithmus implementiert. Damit liefert die Ähnlichkeitssuche jetzt in fast allen Fällen „intuitive“ Ergebnisse.
Das Ergebnis
Wie sieht das konkret aus? Sobald man beim Anlegen einer neuen Person den Nachnamen „Kraus“ eingibt, werden automatisch folgende ähnliche Namen angezeigt:
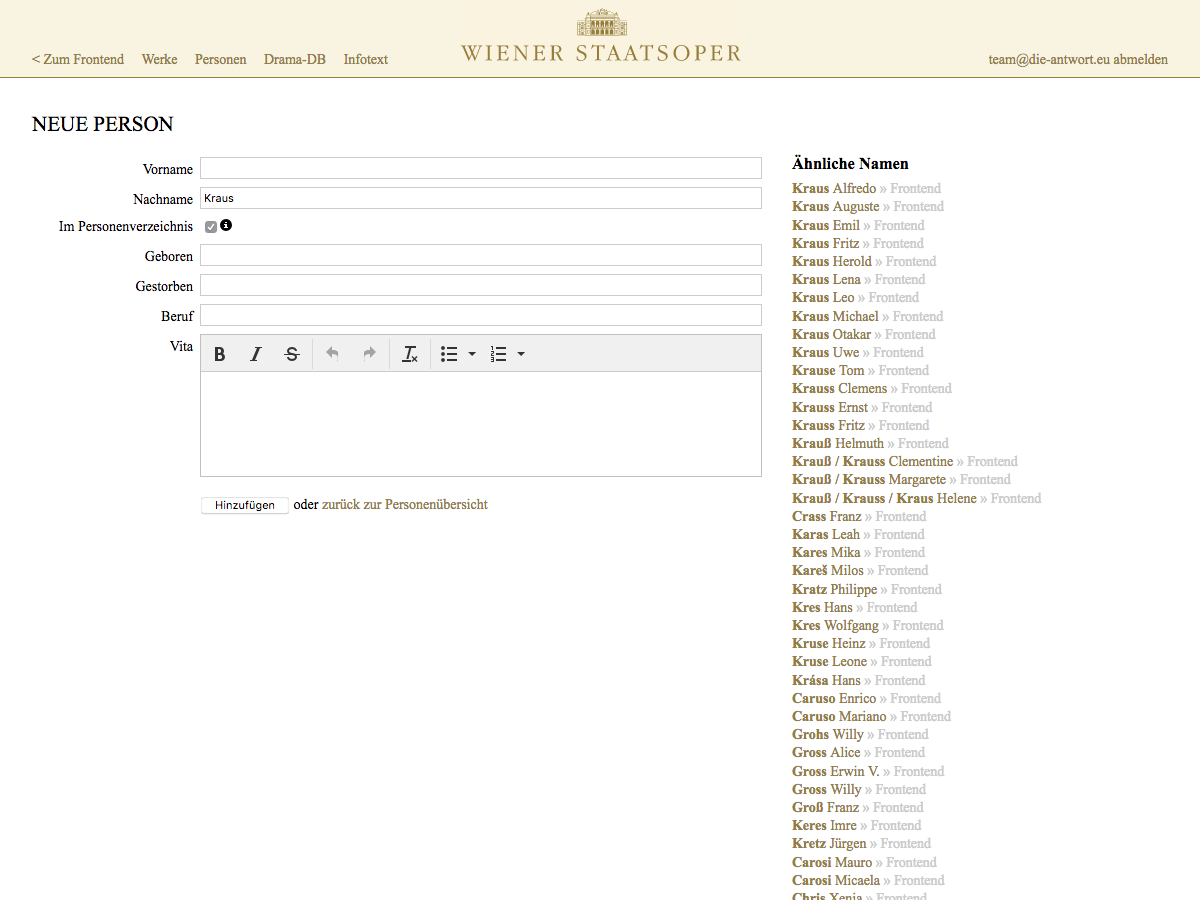
Gefunden werden nicht nur naheliegende ähnliche Schreibweisen wie „Krauss“ oder „Krauß“, sondern auch Namen, die ganz anders geschrieben werden, aber trotzdem ähnlich klingen, zum Beispiel „Crass“ oder „Gross“.
Damit kann jetzt also gleich beim Anlegen einer neuen Person überprüft werden, ob diese Person – eventuell mit anderer Schreibweise – bereits in der Datenbank existiert. Doppeleintragungen sollten in Zukunft also nicht mehr vorkommen.
P.S.: Open Source
Wir nutzen uns in unseren Projekten fast ausschließlich Open-Source-Software, und bemühen uns, auch selbst einen Teil zu diesem Ökosystem beizutragen.
Die im Rahmen dieses Projekts entwickelte Implementierung der Kölner Phonetik haben wir daher als Open-Source freigegeben, und Stefan hat dazu beim vienna.rb-Meetup einen Talk gehalten:
Next up! @noniq enlightening us on German phonetics 🗣👤 pic.twitter.com/7qj8ogCB3E
— vienna.rb (@viennarb) 8 March 2018
Wir beschäftigen uns täglich mit maßgeschneiderten Datenbanken und allem, was dazugehört – Suche, Datenmigration, Anbindung an externe Schnittstellen.